【生成AI】ハルシネーションの原因とその対策

生成AIの普及に伴い、様々な問題が浮き彫りになってきました。その中の一つに、ハルシネーションという問題が指摘されています。本記事では、ハルシネーションの発生原因と企業が取り組むべき対策について詳しく解説します。
また弊社開催ウェビナーアーカイブ「生成AIで社内データを活用するために必要なこととは?」では、プロンプトエンジニアリングやRAGについて詳しく紹介しております。
企業向けChatGPT活用サービス
ウェビナーアーカイブ
ハルシネーションとは
ハルシネーションとは、生成AIが事実とは異なったもっともらしい誤情報を生成する現象です。この現象は、生成AIが学習しているデータの質や量に大きく依存します。特に、テーマに対する学習データの偏りや不足があると、生成AIは不正確な情報を生成することがあります。 このような誤った情報を鵜呑みにしてしまうことで、法令違反や権利侵害、企業の信頼低下などのリスクがあります。
生成AI活用の注意点については以下の記事をご覧ください。

データセットの品質
生成AIは事前に学習した大量のデータから回答を生成しますが、学習するデータには誤った情報もあります。生成AIは情報の正誤を判断することができないため、誤った回答を生成することがあります。また、生成AIの学習データが特定の分野、言語、文化、地域に偏っていると、その偏りを反映した回答を生成します。
生成AIモデルの構造
大規模言語モデル(LLM)は大量のパラメータを持ち、それによって非常に多くのパターンを学習することができます。ただし、その複雑さが逆に誤った関連性やパターンを生成してしまう原因にもなります。
生成AIが不正確な情報を生成する現象
学習データの不足によって偏りや誤りが生じ、事実に基づかない情報を生成することがあります。例えば、実際に存在する会社や組織・既存のサービスにも関わらず、誤った情報を生成することがあります。

株式会社リンクレア(Linklears INC.)は、正しくは株式会社リンクレア(LINCREA)です。
また、設立年月日も本社所在地も異なります。正しくは以下の会社概要にある通りです。
- 設立:1970年1月(昭和45年)
- 本社住所:東京都港区港南2丁目16番3号品川グランドセントラルタワー23F
- 事業内容:コンサルテーション、システム構築、セミナー/システム教育

※斯波義廉と斯波義敏の所属が東西逆になっています。

かなり抜け漏れがある上、8番の石舟岳に関してはそもそも存在しません。
プロンプトエンジニアリング
プロンプトエンジニアリングとは、生成AIから望ましい回答を得る為に、ユーザが指示や命令(プロンプト)を設計するプロセスです。指示や命令を詳細に定義することで、生成AIがより正確に文脈を理解し、正確な回答を得ることができます。 例えば指示・命令だけではなく、役割、前提条件やインプットを定義し、どのようなアウトプットを求めるかまで指定することで、期待通りの回答を得ることが可能です。
特徴
- コストがかからない
- プロンプト記述の知識が必要
- 一時的にしかデータのインプットができず、データセットそのものに知識の追加ができない
ファインチューニング
ファインチューニングとは、生成AIが事前に学習したモデルの一部または全体に対して、別の新しいデータを学習させることで、特定の目的やタスクに応じたアップデートを行うことです。
以下がファインチューニングの主な流れです。
基本的な流れ
- 特定の目的やタスクに適応するデータセットの準備
生成AIが目的やタスクに適した回答ができるよう、目的に合わせたデータセットを準備します。例えば、医療分野で生成AIを扱う場合、医療関連のデータセットを用いてファインチューニングします。 - 既存モデルの利用
最初からモデルを構築するのではなく、既存のLLM(GPTなどの大規模言語モデル)を活用します。これにより、基本的な言語能力や知識を持つモデルから出発できるため、学習プロセスが効率化されます。 - 学習の実行
準備したデータセットを用いて、学習します。 - 評価
必要な回答が得られているかを確認します。必要に応じて、新たなデータを追加して、回答精度の向上を図ります。
特徴
- 特定のタスクにあった性能を発揮できる
- LLM全体を特定のタスク用に学習させる
- 学習データの準備に時間がかかる
RAG
RAG(Retrieval-Augmented Generation、検索強化生成)とは、保有データや外部のデータから関連性のありそうな情報を検索し、回答を生成することを言います。そうすることで、生成AIが事前学習していなくても回答できるようになったり、回答精度や専門性の向上が見込めます。
RAGの始め方については以下の記事をご覧ください。

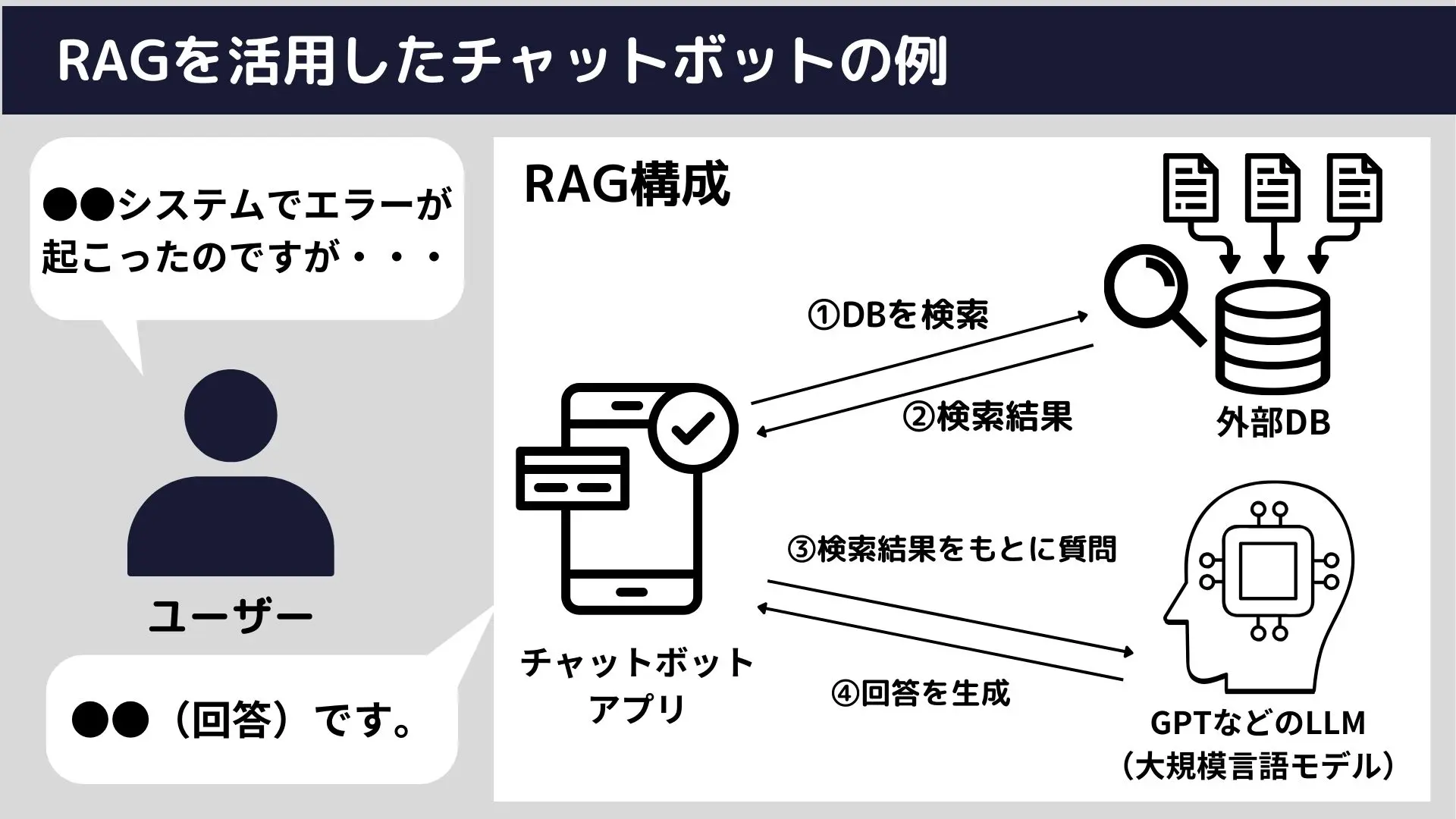
基本的な流れ
- 指示の解析
ユーザーからの質問や指示を受け取り、キーワードや重要な用語を解析します。 - 情報の検索
上記で解析したキーワードをもとにデータベースや文書から関連する情報を検索します。 - 情報の統合と生成
検索結果とユーザーからの指示を組合わせたプロンプトを生成AIに入力し、回答を取得します。 - 回答の最適化と調整
最後に、生成された回答がユーザーの質問に最適であるかを確認し、必要に応じて文言を調整します。これには、文脈の整合性や情報の正確性が考慮されます。
特徴
- 既存のデータソース(例えば社内のPDFやExcel)からテキスト情報を抽出できるため、追加データの準備の手間があまりない
- 検索と生成の2つの機能を最適化するための専門性を必要とする
- 専門的知識を取り扱う業務のFAQやカスタマーサポートを実現することが可能
ハルシネーション対策:生成AI活用に向けた体制の整備
ハルシネーション対策は、前述のような技術的アプローチだけでは不十分です。技術的な対策だけでなく、ユーザーのリテラシー教育、ガイドラインの作成・教育、体制面を整備することで、よりハルシネーションリスクを低減することができます。
- ユーザーへの教育
・生成AIの仕組みやそのメリット・デメリットの理解と、リテラシー向上に向けた教育 - ファクトチェックの徹底
・回答結果が誤った情報や不正確な内容ではないか確認・検証し、情報の信頼性を担保
・ファクトチェックのプロセスと体制の構築 - 信頼性の高いサービスの選定
・ハルシネーション対策が十分に施された信頼性の高い生成AIサービスの選定 - ガイドラインの整備と適切な監査体制の構築
・生成AIの利用目的、適用範囲、責任範囲などを明確に定義したガイドラインを作成
・ガイドラインの運用状況の監査と体制構築
まとめ
ハルシネーションの完全な対策は難しいですが、技術的な対策に加えて、体制構築や教育を徹底することで一層のリスク低減ができます。 生成AIはビジネスや業務の質を向上させる新たな技術です。生成AIの特徴やリスクを正しく理解し、積極的に活用していきましょう。
「生成AIで社内データを活用するために必要なこととは?」では、ハルシネーション対策:技術的アプローチにあげたプロンプトエンジニアリングやRAGについて詳しく紹介しております。ご覧いただき、安全な生成AI活用に関する知見を深めていただければと思います。

生成AIに関するお問い合わせはこちら >





