RAGをはじめるためには?生成AIで社内データを活用するための工夫

生成AIを活用した課題解決や業務改善を目指す動きが広がりつつあります。しかし、生成AIはインターネット上に公開された情報に基づいて学習し回答を生成するため、社内の内部情報やナレッジに関する質問への適切な回答が難しい場合があります。そこで、独自に構築したLLM※1と外部データを組み合わせて、より正確で信頼性の高い回答を生成するRAG(Retrieval-Augmented Generation)の導入が注目されています。
本記事では、RAGについて情報収集をされる方に向けて、RAGの基礎知識や導入方法について詳しく解説します。 また、ダウンロード資料ではRAGの回答精度向上事例をご紹介しておりますので、ご興味のある方は是非ご一読ください。
※1 LLM(Large Language Models):大規模言語モデル
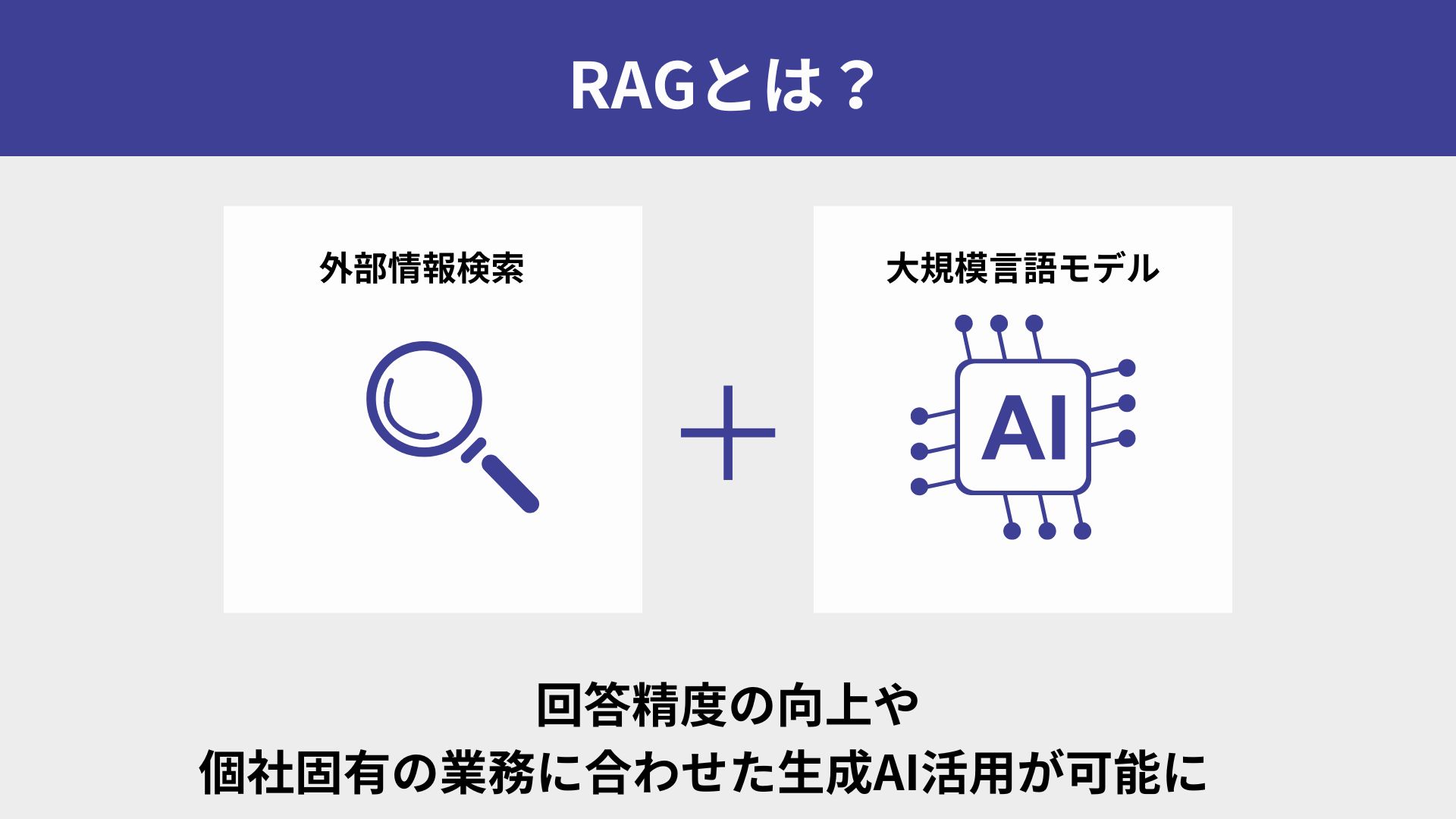
RAGは、LLMと外部情報の検索を組み合わせることで回答精度を向上させる技術です。従来の生成AIとは異なり、最新情報の反映や専門的な情報の活用ができるようになり、より正確な回答を生成することができます。
また、企業固有の知見や業務情報に基づいた回答も可能になります。

RAGの基本的な仕組み
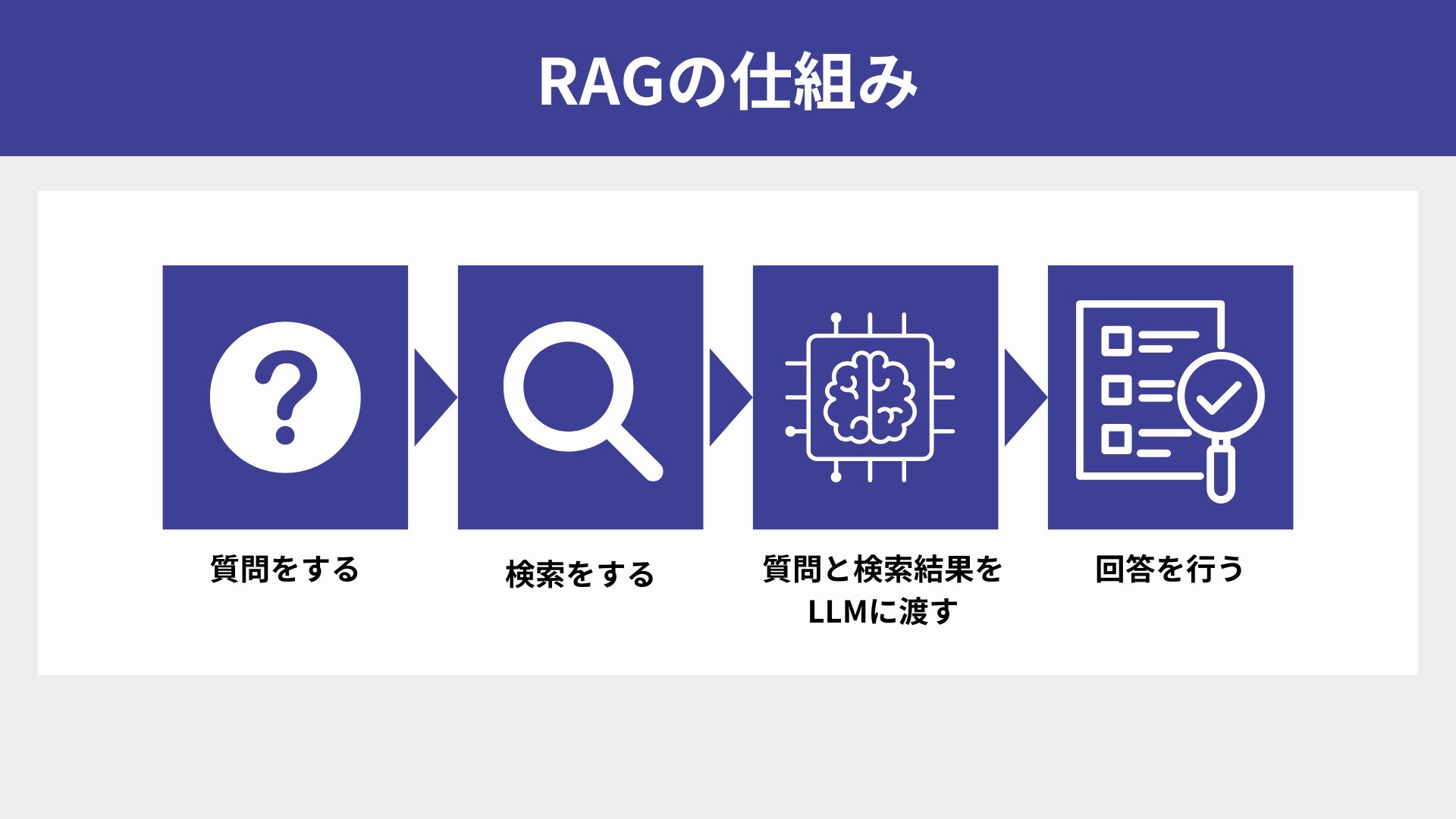
RAGは、検索(Retrieval)と生成(Generation)の二つのフェーズで構成されています。検索フェーズでは、ユーザーの質問に対して外部の情報源を検索し、情報を収集します。生成フェーズでは、検索フェーズで収集した情報を基に、LLMが精度の高い回答を生成します。
基本的な流れ
1.指示の解析
ユーザーからの質問や指示を受け取り、キーワードや重要な用語を解析します。
2. 情報の検索
解析されたキーワードをもとに、データベースや文書から関連する情報を検索します。
3. 情報統合と生成
検索結果とユーザーからの指示を組合わせたプロンプトを生成AIに入力し、回答を取得します。
4. 回答の最適化と調整
生成された回答がユーザーの質問に最適であるかどうかをシステム上で確認し、必要に応じて文言を調整します。この際、文脈の整合性や情報の正確性を考慮します。
RAGとファインチューニングの違い
RAGとファインチューニングは、どちらも生成AIの回答精度・品質を向上させる技術ですが、大きな違いは生成AIに学習させるか否かという点です。
ファインチューニング
ファインチューニングとは、特定のタスクに対してモデルを最適化する手法です。特定のデータセットに基づいてモデルを調整するため、生成AIの回答方法やプロセスを変更することが可能です。自然言語の生成結果に影響を与えるため、社内のミッションや文化、言葉といった「自社らしい回答」を提供するのに適しています。 一方で、モデルそのものに対して細かなチューニングが必要であり、比較的高いコストがかかる傾向にあります。
RAG
RAGとは検索と生成を組み合わせた手法です。RAGの技術を活用することで、より広範な情報を扱うことができるため、汎用性が高く、多様な質問に柔軟な対応ができるようになります。検索先のデータベースに存在する知識を回答に付与するのであれば、学習コストが少ないRAGが適しているといえます。
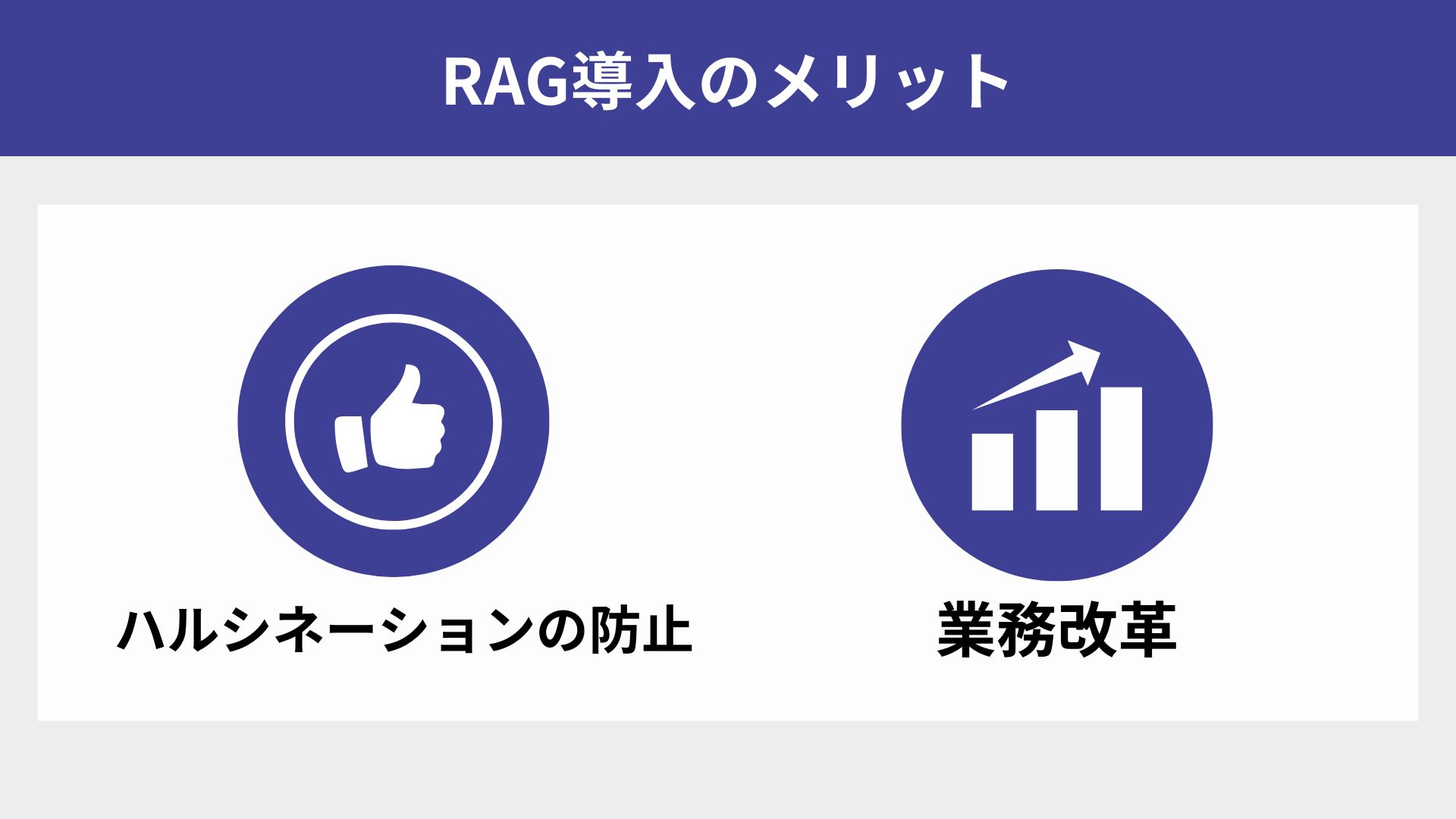
RAGの最大の特徴は外部情報を検索し、LLMがその検索結果に基づいて回答を生成する点にあります。これにより従来の生成AIと比べ、業務適用の範囲が広くなるだけでなく、以下のようなメリットが得られます。
高品質な回答が得られる
RAGはユーザーの質問に関連する情報を検索することで、独自に構築したLLMの持つ学習データの不足を補い、誤った回答(ハルシネーション)を防ぐことができます。

専門知識を補完できる
RAGは、外部の情報源や企業内のデータベースから専門的な情報を検索し、独自に構築したLLMの学習データを補完することができます。これにより、専門的な質問への回答だけでなく、出典元(引用データ)を添付することができるため、専門的な知識に乏しい担当者でも専門的な情報を効率的に取り扱うことができるようになります。
社内問い合わせ対応
社内の問い合わせ対応にRAGを活用することで、社員からの問い合わせに対して効率的に回答することができます。例えば、ITサポートやバックオフィス業務の問い合わせ対応にRAGを導入することで、頻繁にある問い合わせや質問に対して迅速な対応ができるようになります。
ダウンロード資料ではRAGを使った社内問い合わせシステムの事例を紹介しています。
カスタマーサポート
カスタマーサポート業務にRAGを活用することで、業務の効率化や顧客満足度を向上させることができます。例えば、製品の使い方や困りごとに関する問合せに対して、迅速に回答できるだけでなく、製品知識の乏しい担当者でも回答できるようになります。
応答時間が長くなりやすい
RAGは検索と生成のプロセスが複雑なため、応答時間が長くなることがあります。しかし、検索アルゴリズムの最適化やキャッシュ機能を活用することで、応答時間を短くすることができます。
検索精度を向上させる工夫が必要
RAGの回答は、正規化されていないデータだと回答精度が安定しないため、事前にデータの正規化を行う必要があります。また、回答精度の維持には、定期的なデータの更新やデータクリーニングを行う必要があります。
定期的なデータのメンテナンスが必要
RAG導入後は、エンドユーザーが検索先のデータ管理を行うことが多いです。データのメンテナンスをしないままでは、古い情報をベースとした回答を生成します。最新データを活用するためには、運用ルールを定めて定期的にデータのメンテナンスを行いましょう。
目的の設定
RAGを活用する目的や、解決したい課題・業務改善の目標を事前に明確にしておくことが重要です。目的の定め方については関連記事にてご紹介しています。

適切なデータソースの選定
検索先となるデータソースを、課題や業務改善の目的に応じて選定します。既に業務で使っているデータソースでも問題はありませんが、検索精度を高めるために正規化されたデータを新たに作ることを検討しましょう。
モデルの選定とトレーニング
生成モデルと検索モデルを目的に応じて選び、トレーニングします。 クラウドプラットフォーム(AWSやAzure)の提供するモデルの利用や既存のシステム、ツールとの連携を鑑みて、最適なものを選びます。
運用・評価
RAGシステムの導入後、事前に設定した目的・目標の達成度を評価し、必要に応じて改善や調整を行います。
まとめ
RAGは、生成AIの関連技術として注目されており、ビジネスの様々な場面で活用され始めています。本記事ではRAGの導入メリットや留意点、そして導入するためのポイントをご紹介しました。RAGを導入する前に、目的の設定から運用・評価までの一連の流れを意識することで、手戻りなくスムーズにRAGを始めることができるでしょう。
リンクレアでは、RAG環境構築の実績がございます。詳しい内容をお知りになりたい方は、お気軽にお問合せ下さい。 また、ダウンロード資料ではRAGの回答精度向上事例をご紹介をしております。
ご興味のある方は是非ご一読ください。

生成AIに関するお問い合わせはこちら >





